
ABBYY FineReader is a must-have tool for translators looking to digitize scanned PDFs and other documents with ease and accuracy. With its support for multiple languages, seamless integration with translation software, and user-friendly interface, ABBYY FineReader is the perfect tool to help you improve your translations and streamline your workflow.
In this article, we will walk you through the entire process of converting a PDF into Word format the TTS NORDIKA way. Enjoy!
To obtain the ABBYY FineReader desktop app, click here.
There is an option to download a free trial if you want to try it out.
1. Setup in ABBYY FineReader
The first step is to set up ABBYY FineReader with the desired settings.
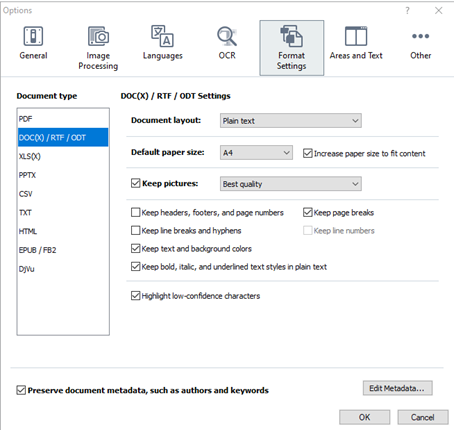
Go to “tools” and choose “options”. We typically use and recommend the following configurations in "Format Settings":
2. Open the PDF you want to Convert
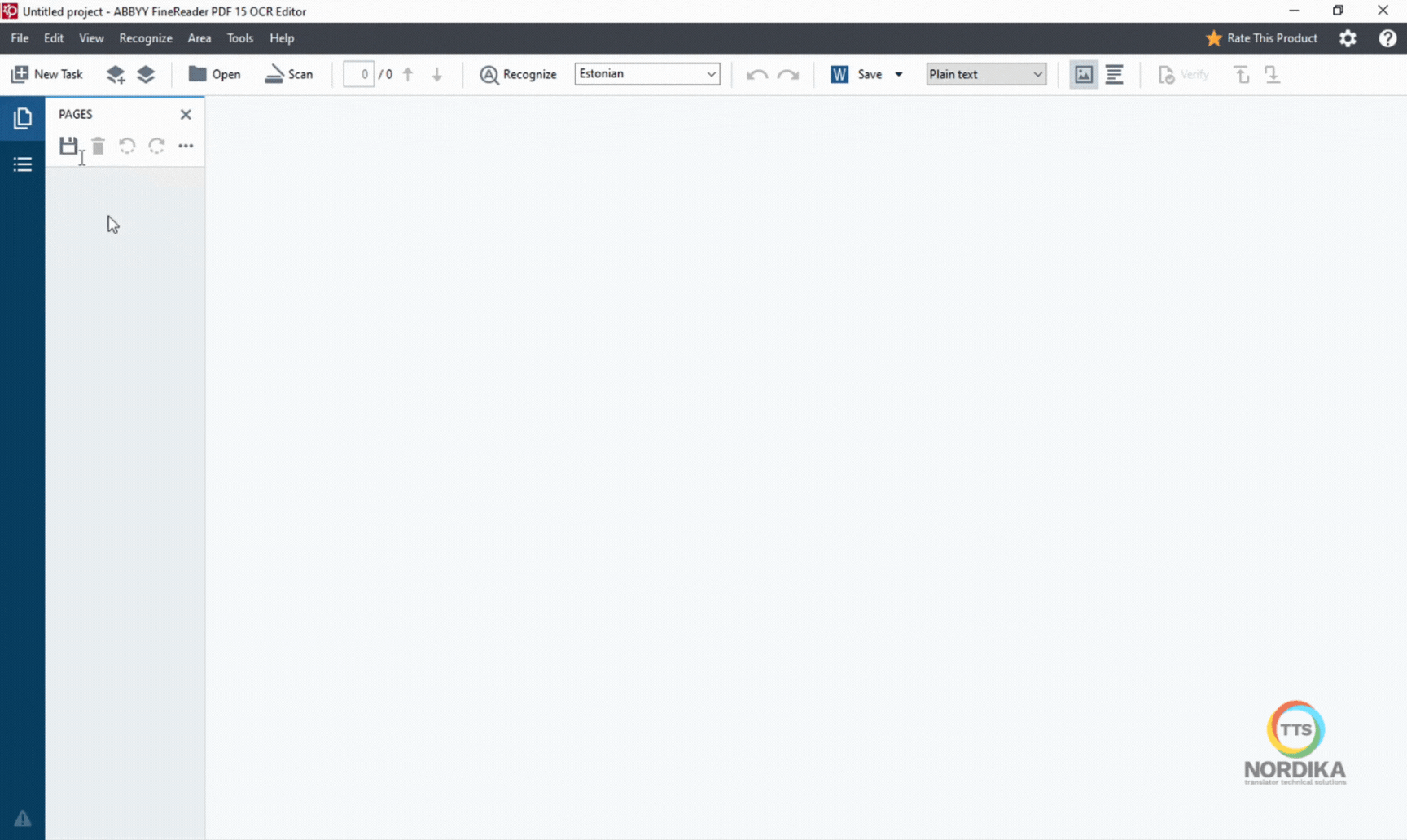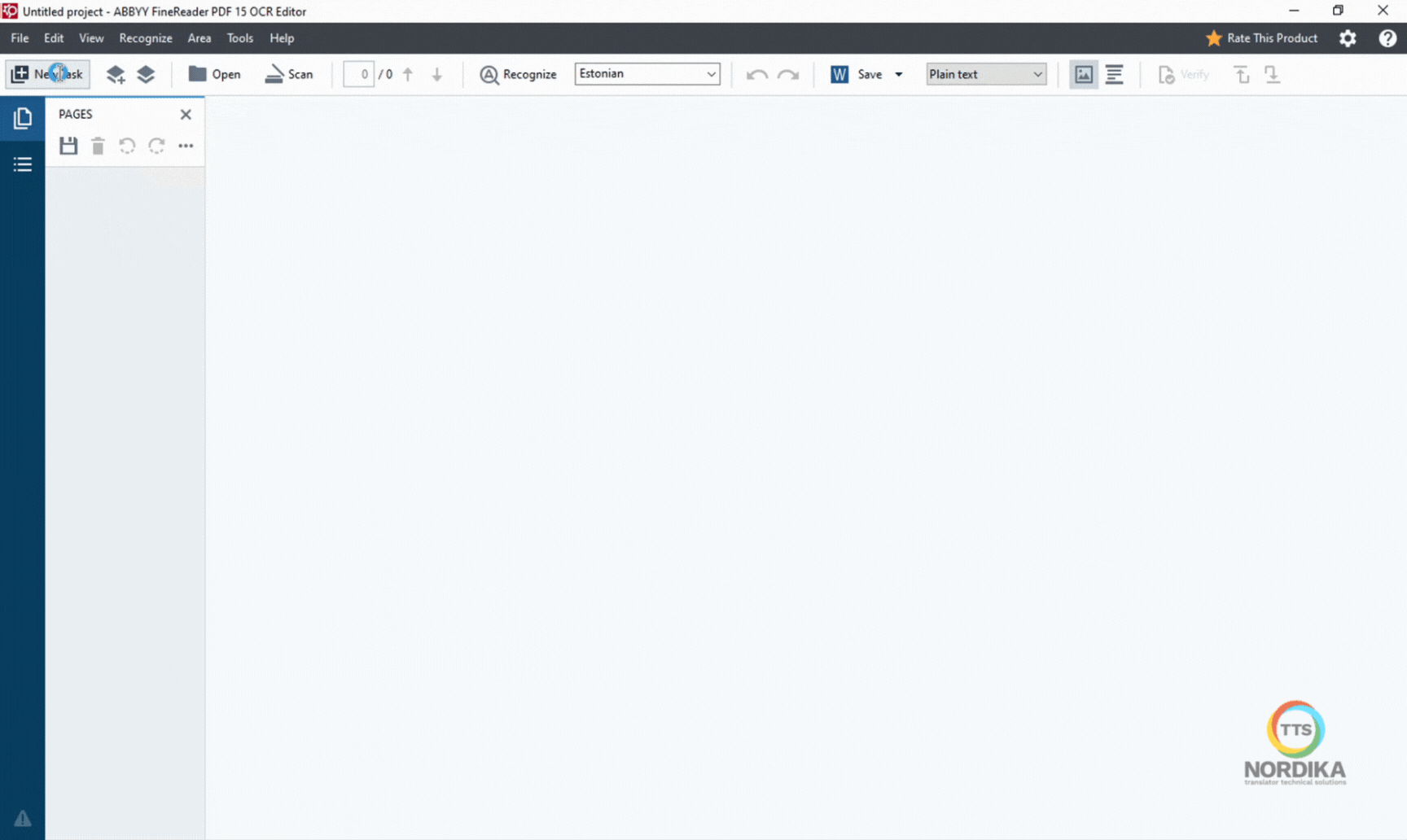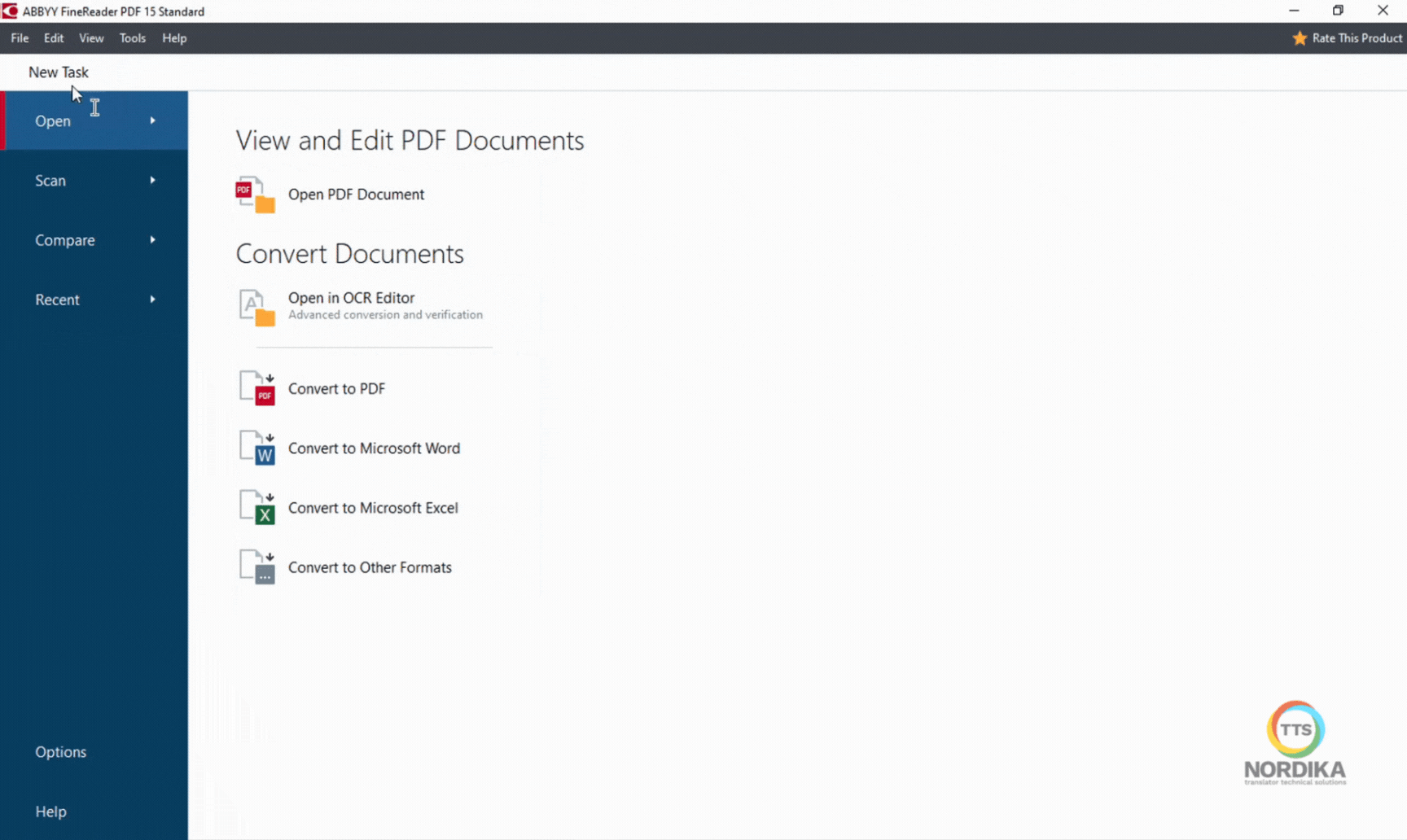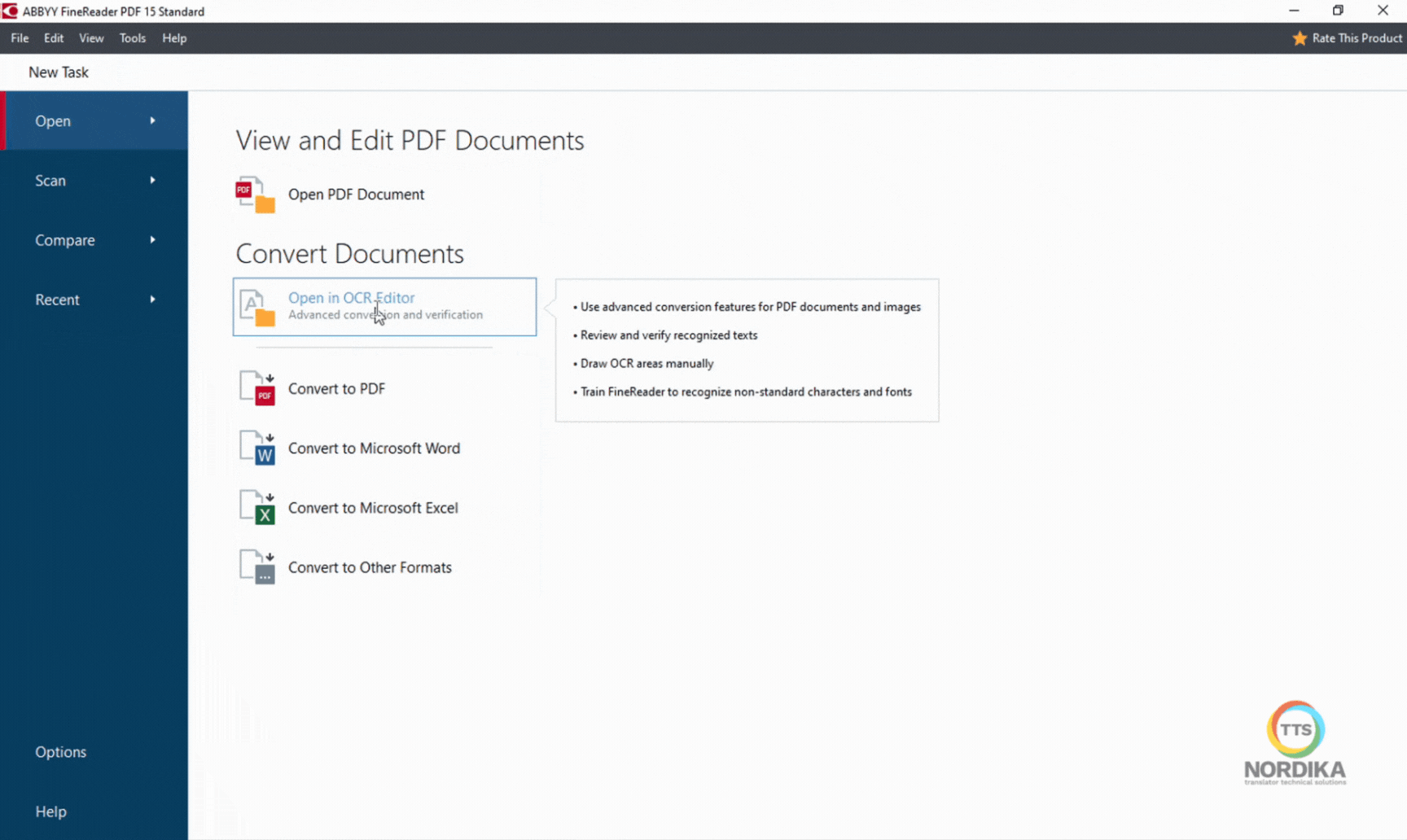
After you have launched ABBYY FineReader, click on "New Task" in the top left corner and choose the "Open in OCR Editor" option. Then, select the PDF file you wish to convert.
The OCR Editor provides powerful features for fine-tuning OCR and conversion processes to achieve optimal results.
3. Set recognition language and saving type
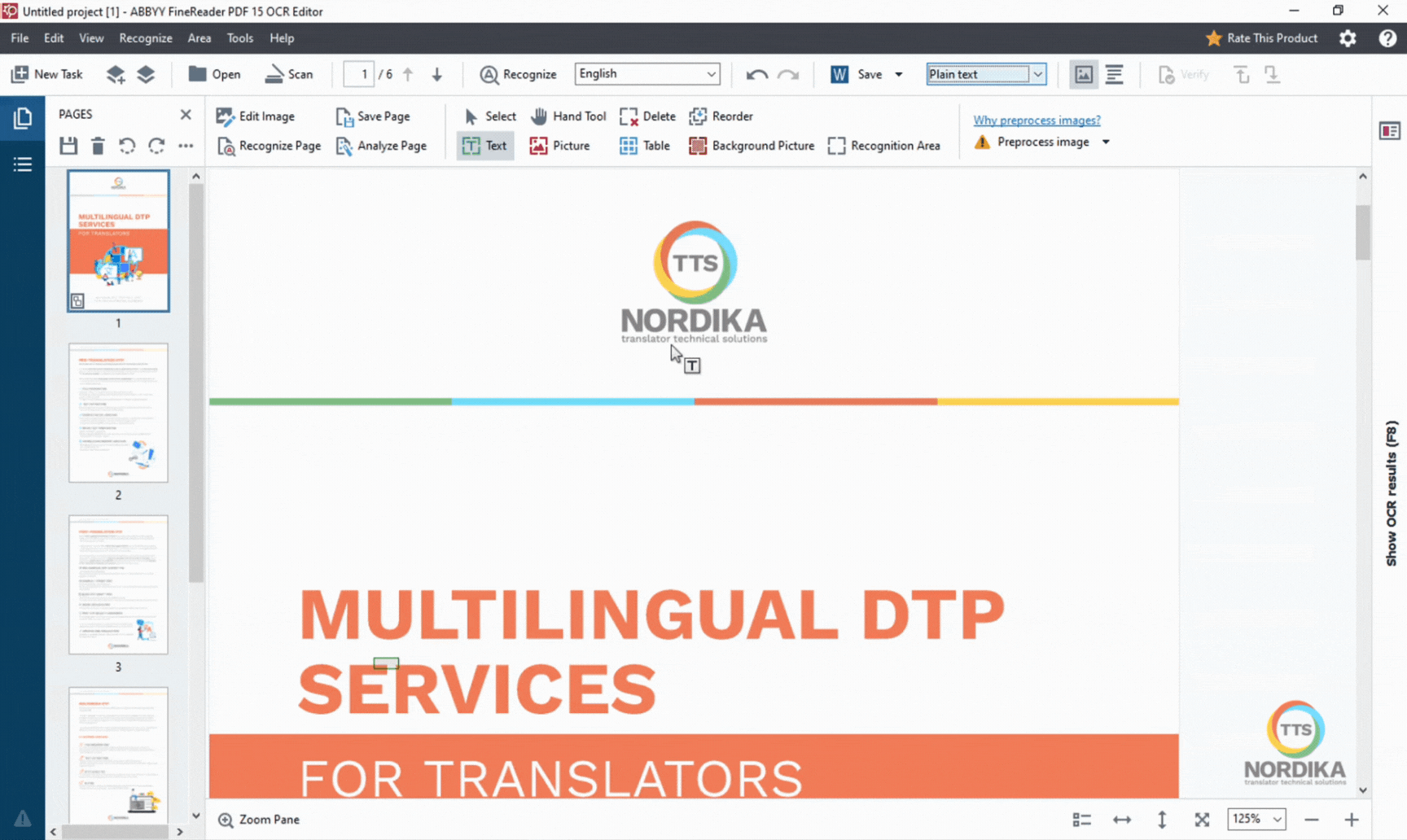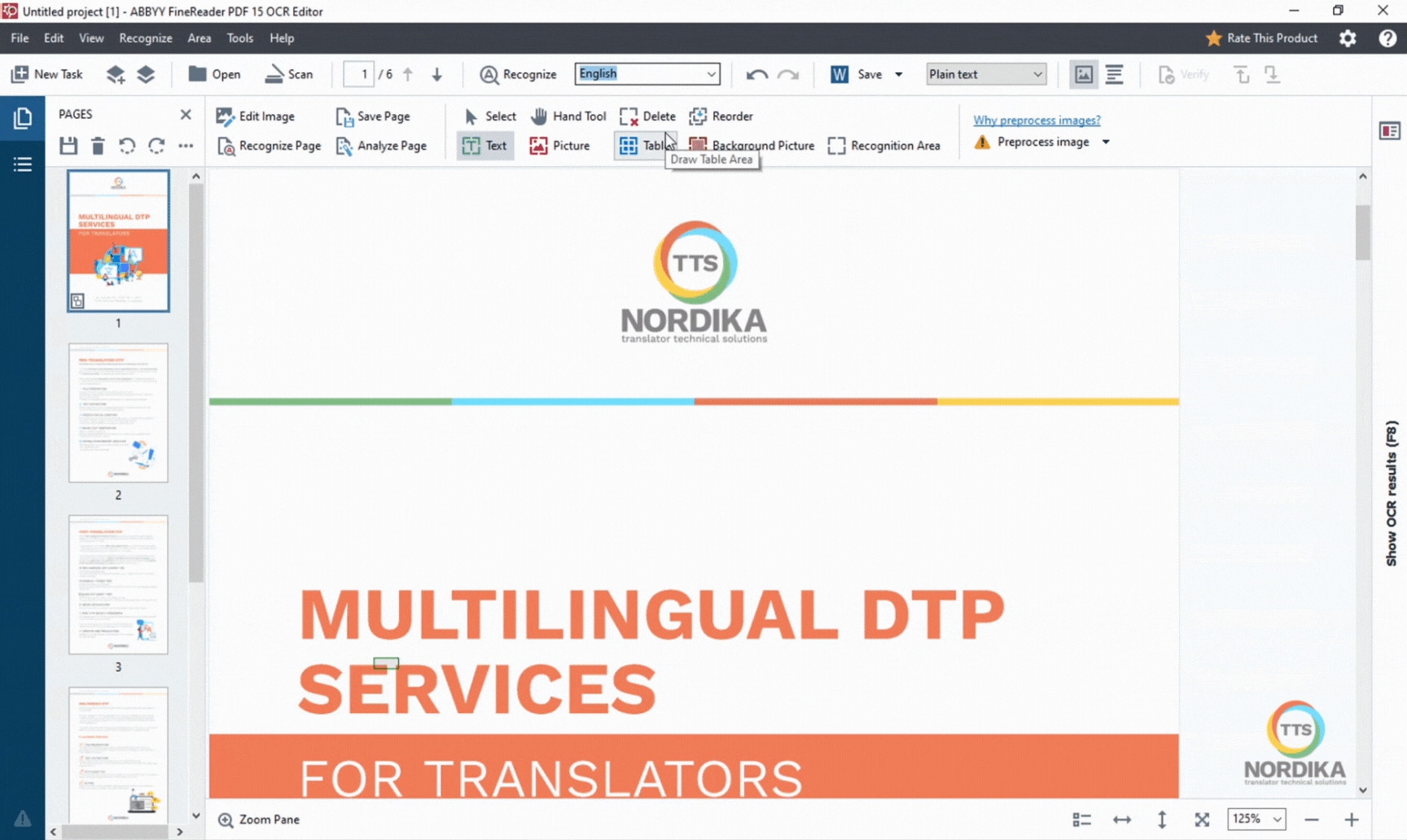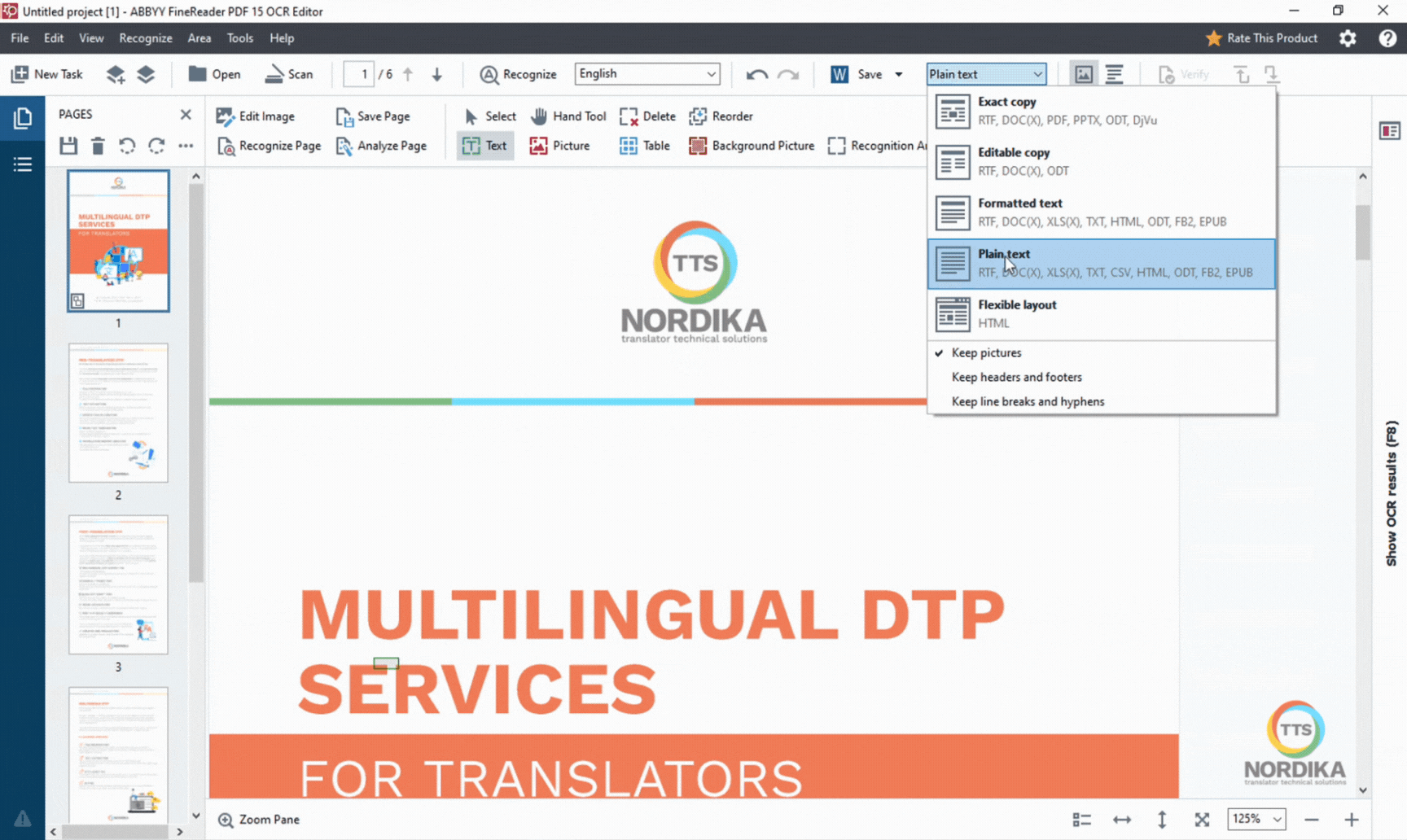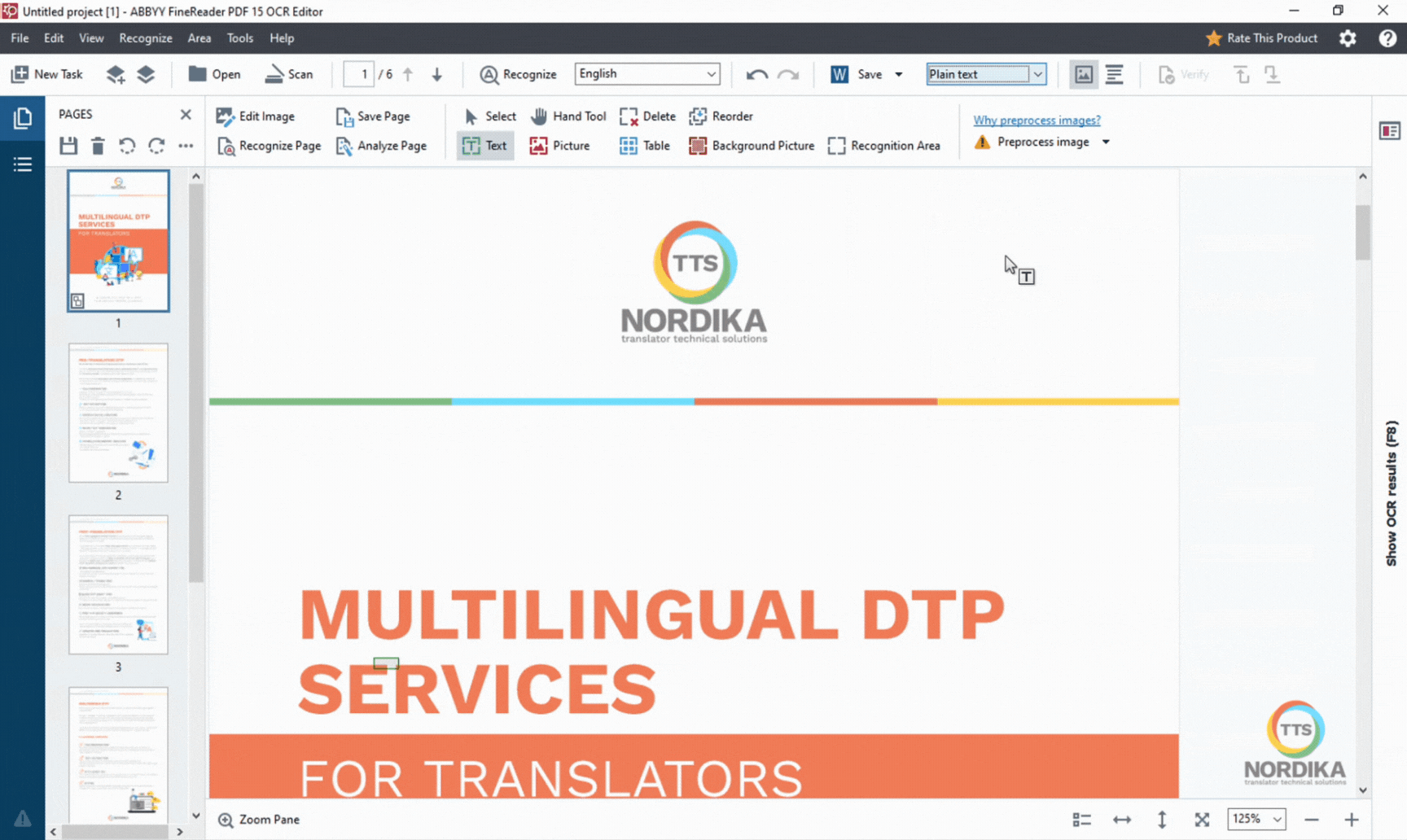
Select the language of the PDF you are processing. If the document contains several languages, select all of them in the list. This is important to ensure that all characters will be accurately converted. Also, make sure that the saving type option is set as “Plain text”. We normally choose this option as we prefer to manually re-create the document layout afterwards (if the document has layout) rather than letting the software re-create it automatically. This gives us greater control over the document and its appearance. You can of course play around with the different options to see what works best for you according to your requirements.
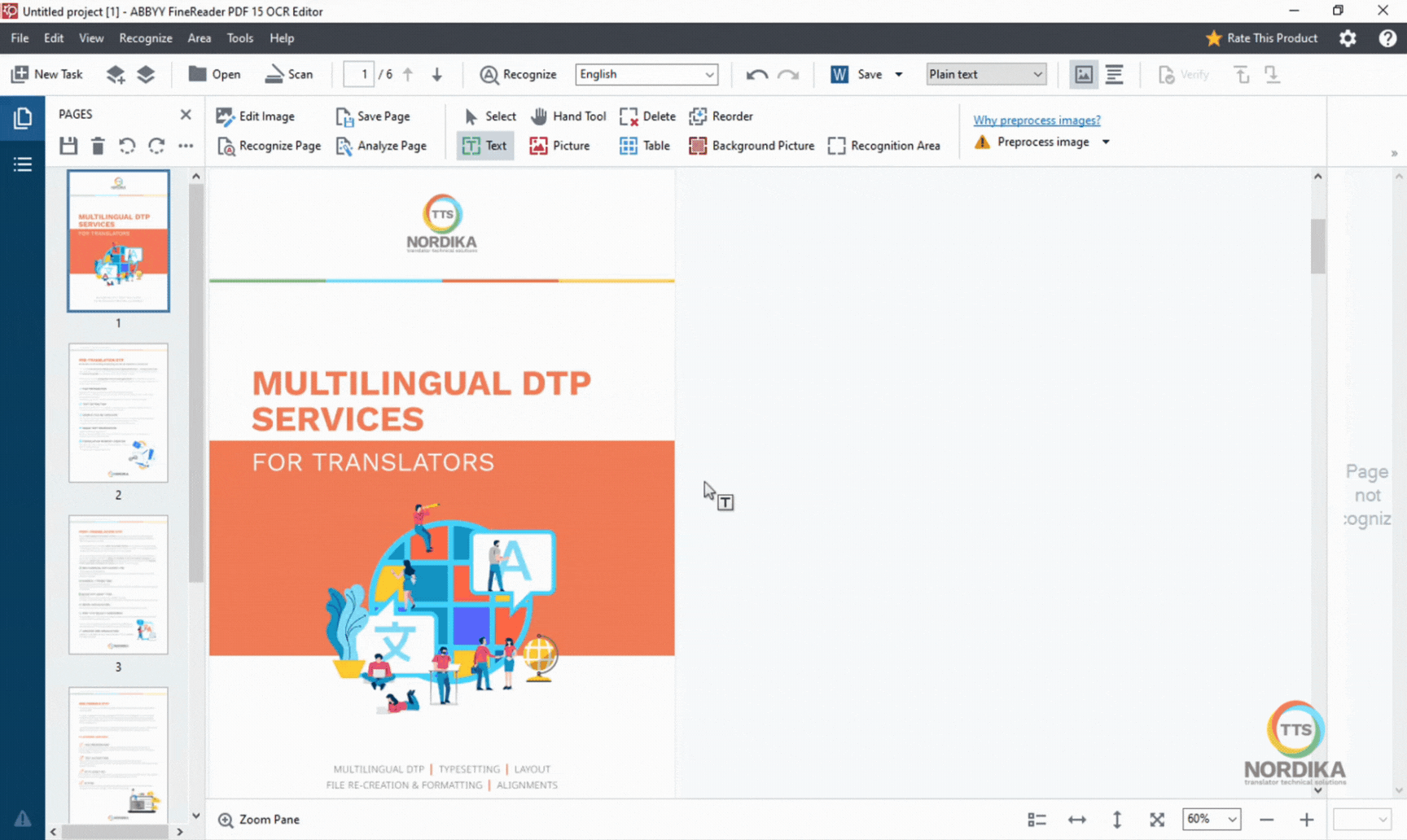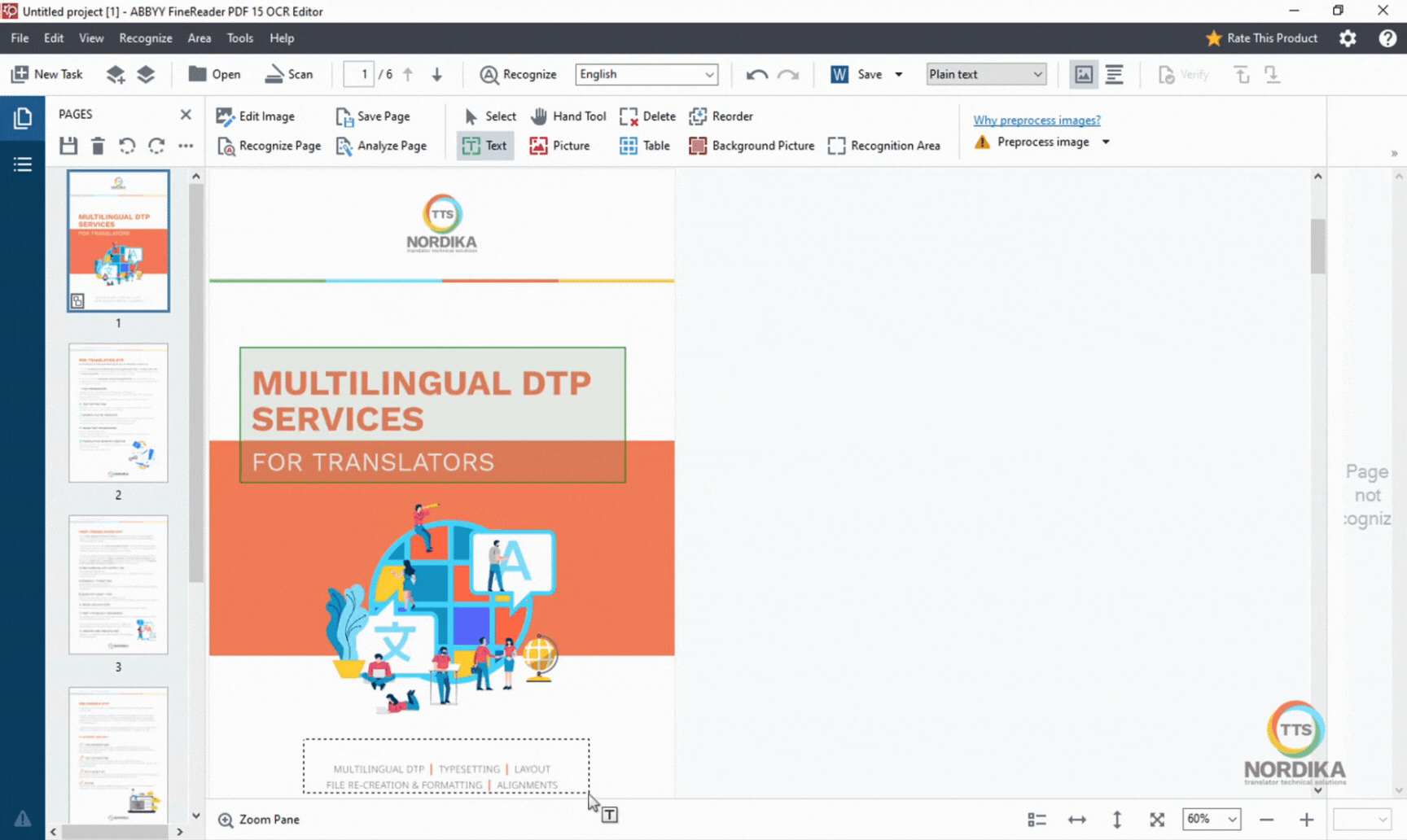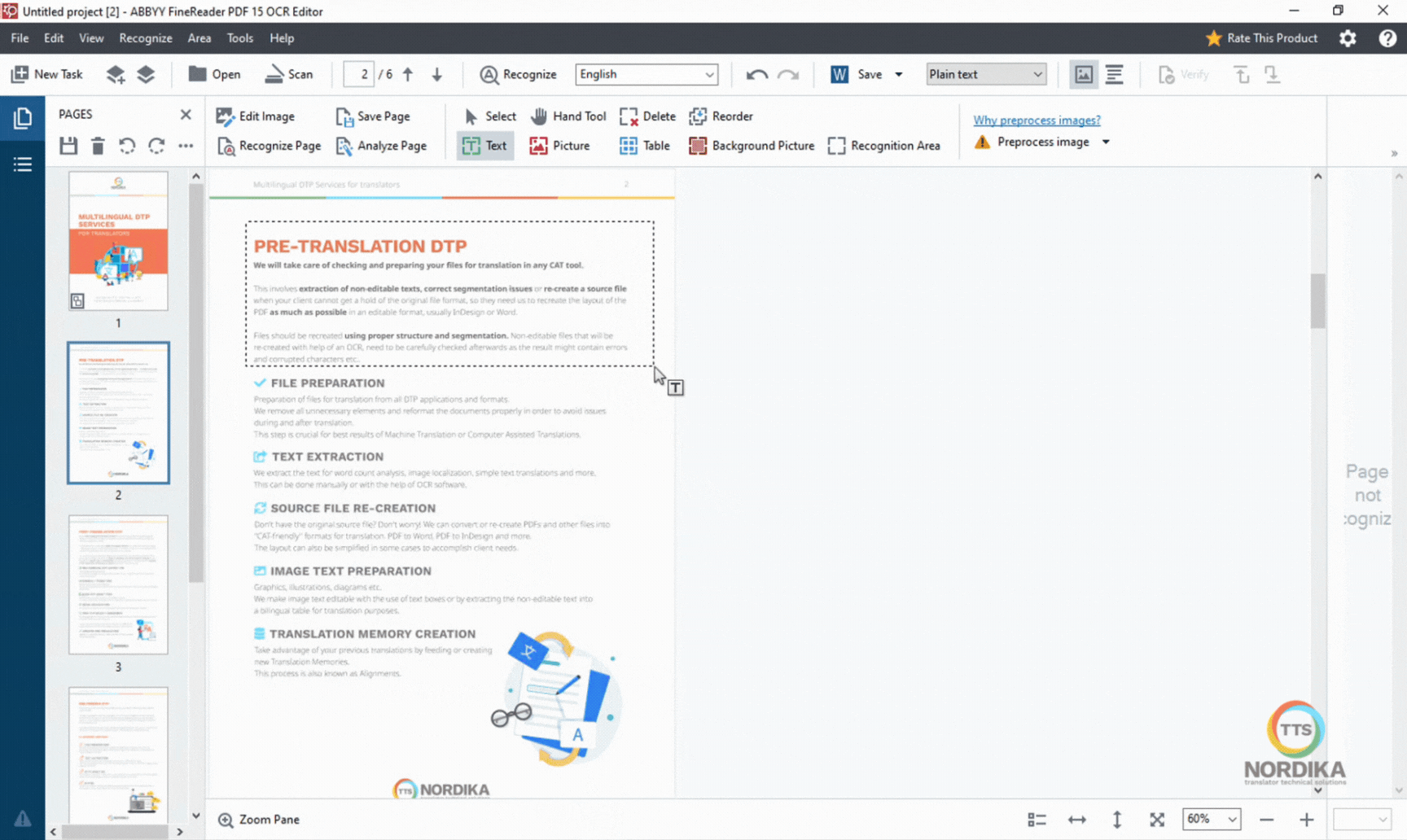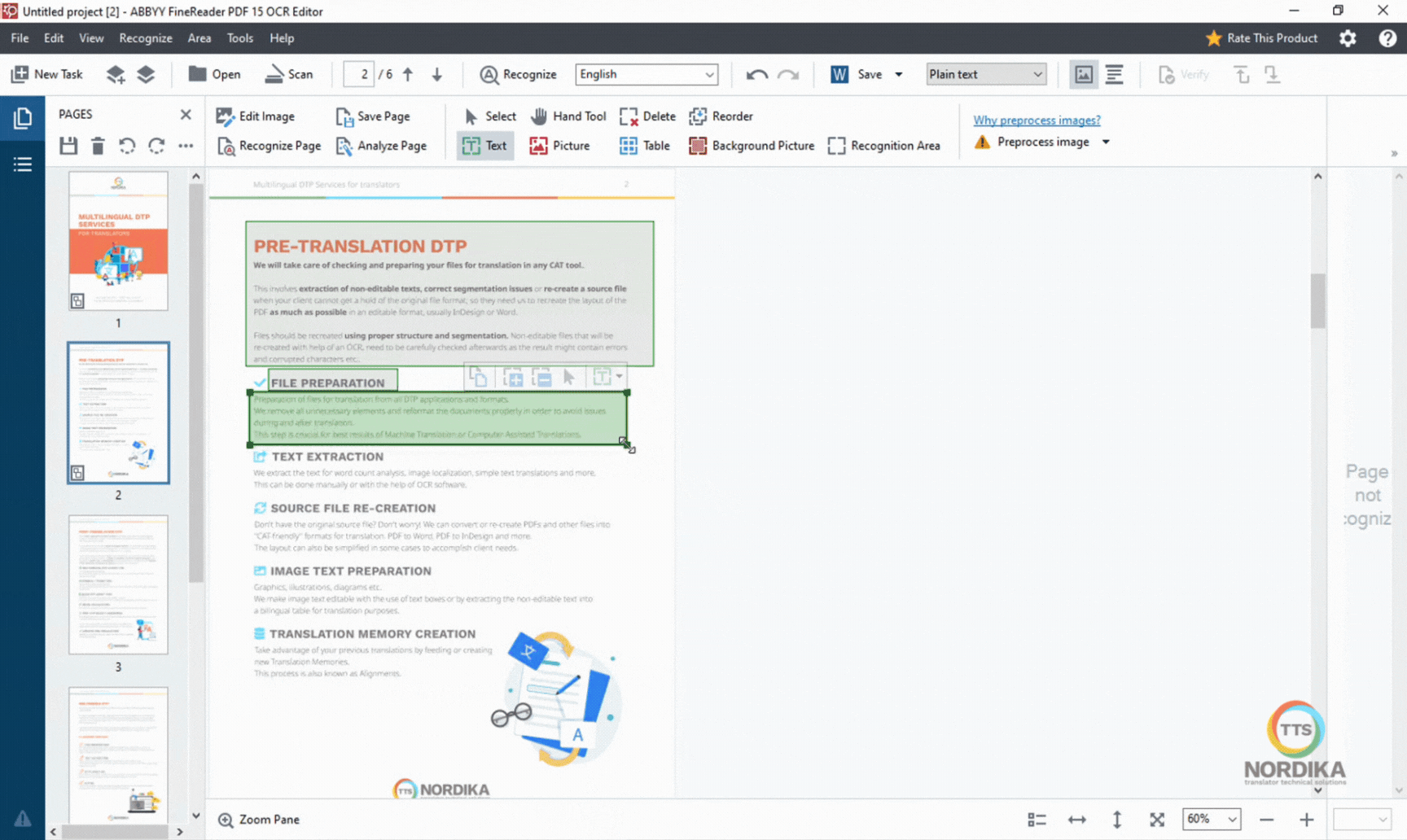
4. Manual area selection
The interface of ABBYY FineReader is highly user friendly, with all the necessary tools conveniently accessible. We will be using the "Draw text area" and the "Draw table area" tool in this demo.

We mainly focus on extracting the text from the PDF, as the images can be inserted orderly in place afterwards once we have the Word document.
With the "Draw text area" tool, you can manually draw a section over the text to select the are.
With the "Draw table area" tool, you can select text that appear in a table structure. If the table in the document doesn't have a clear structure, you can add the rows and columns manually.
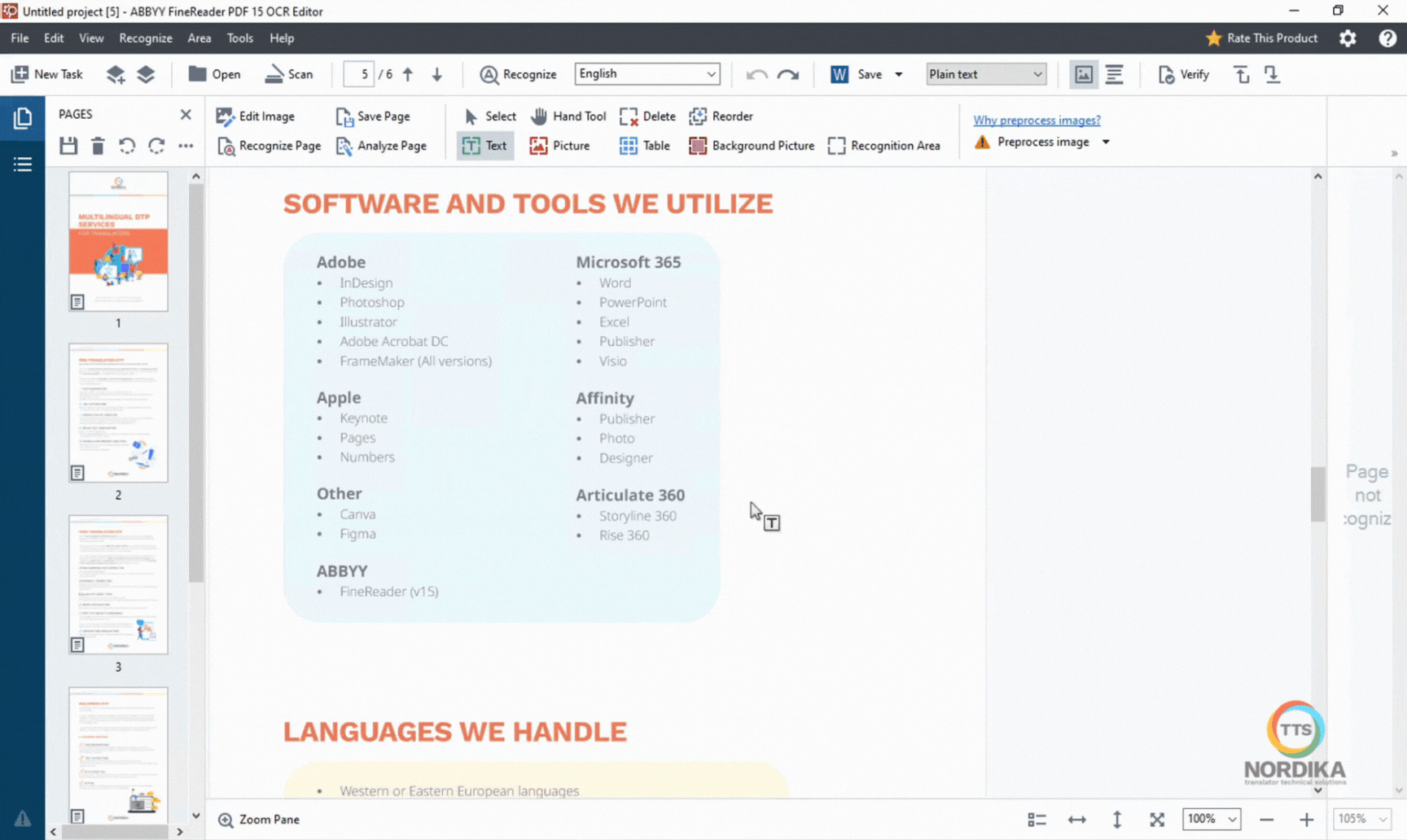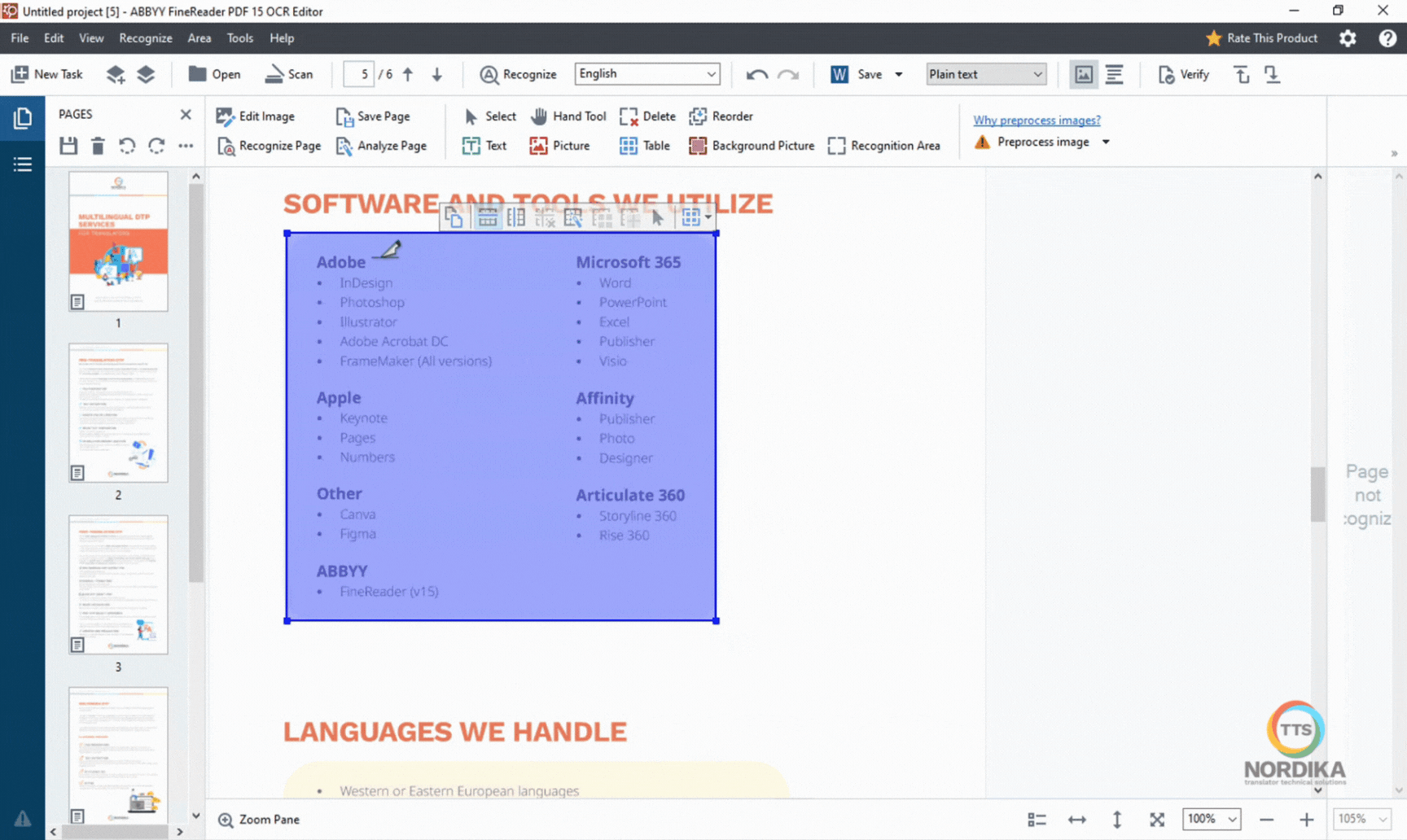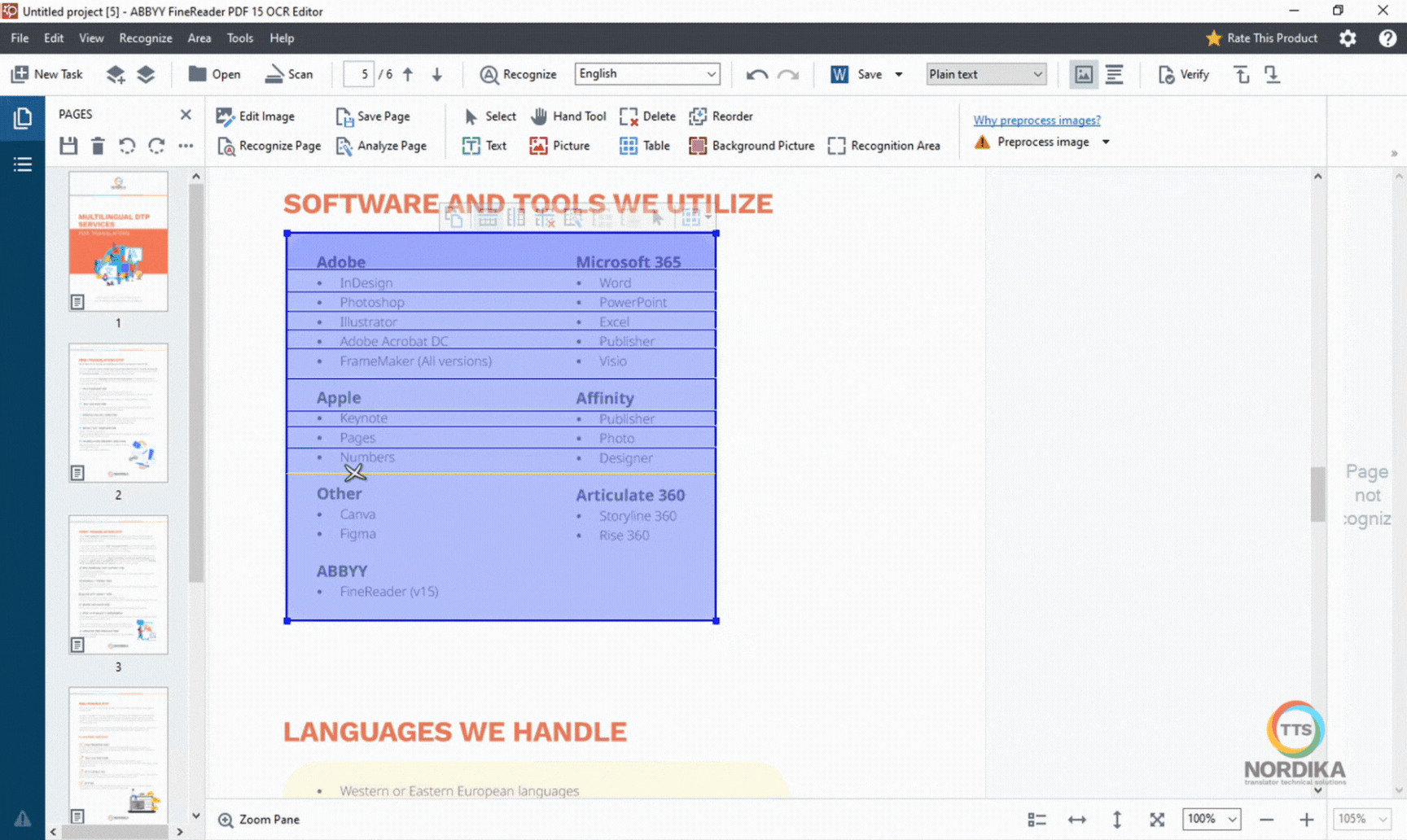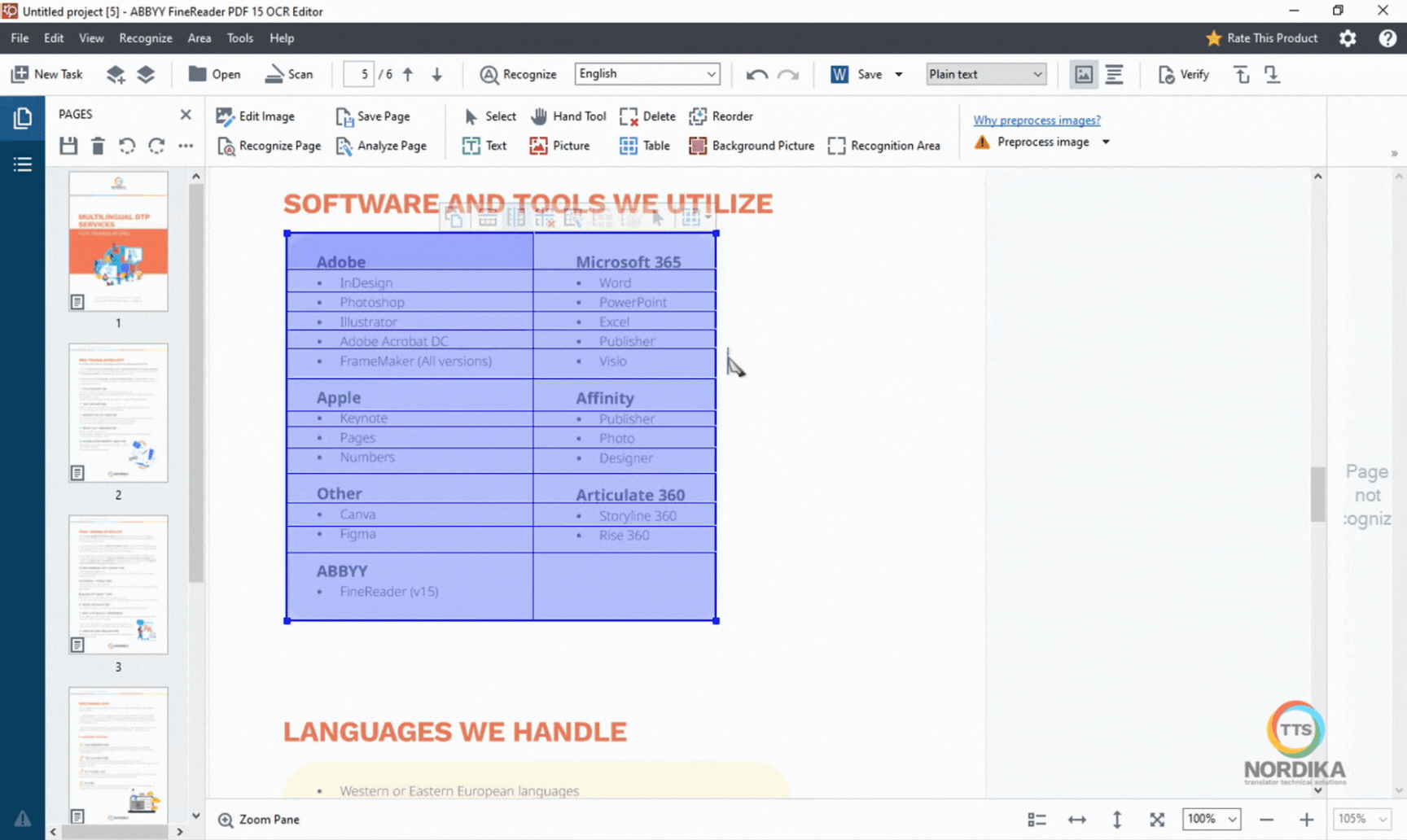
While the manual selection may seem like a time-consuming task, investing more time in this part of the process will significantly improve the quality of the Word document you receive, especially if it is intended for translation.
5. Recognize pages
Once you have selected all text you want to convert, click on the first page, scroll down and while holding the "shift" key, click on the last page. Now that all pages are selected, right click and select “recognize pages”. This step ensure that the text closely matches the original document in terms of content, structure, and formatting. You will receive a message if there is any error, for example if the language(s) has not been selected correctly.
6. Export to Microsoft Word
Now you can export your selections to Microsoft Word. Click on "Save" and "Save as Microsoft Word Document".
Remember when we chose the saving type to "plain text" in the very beginning? Well, this is the result of that. It doesn't look very pretty now, for sure, but it's now when we apply the different styles and formats to the text, as well as adding the images, page numbering, headers and footers etc.
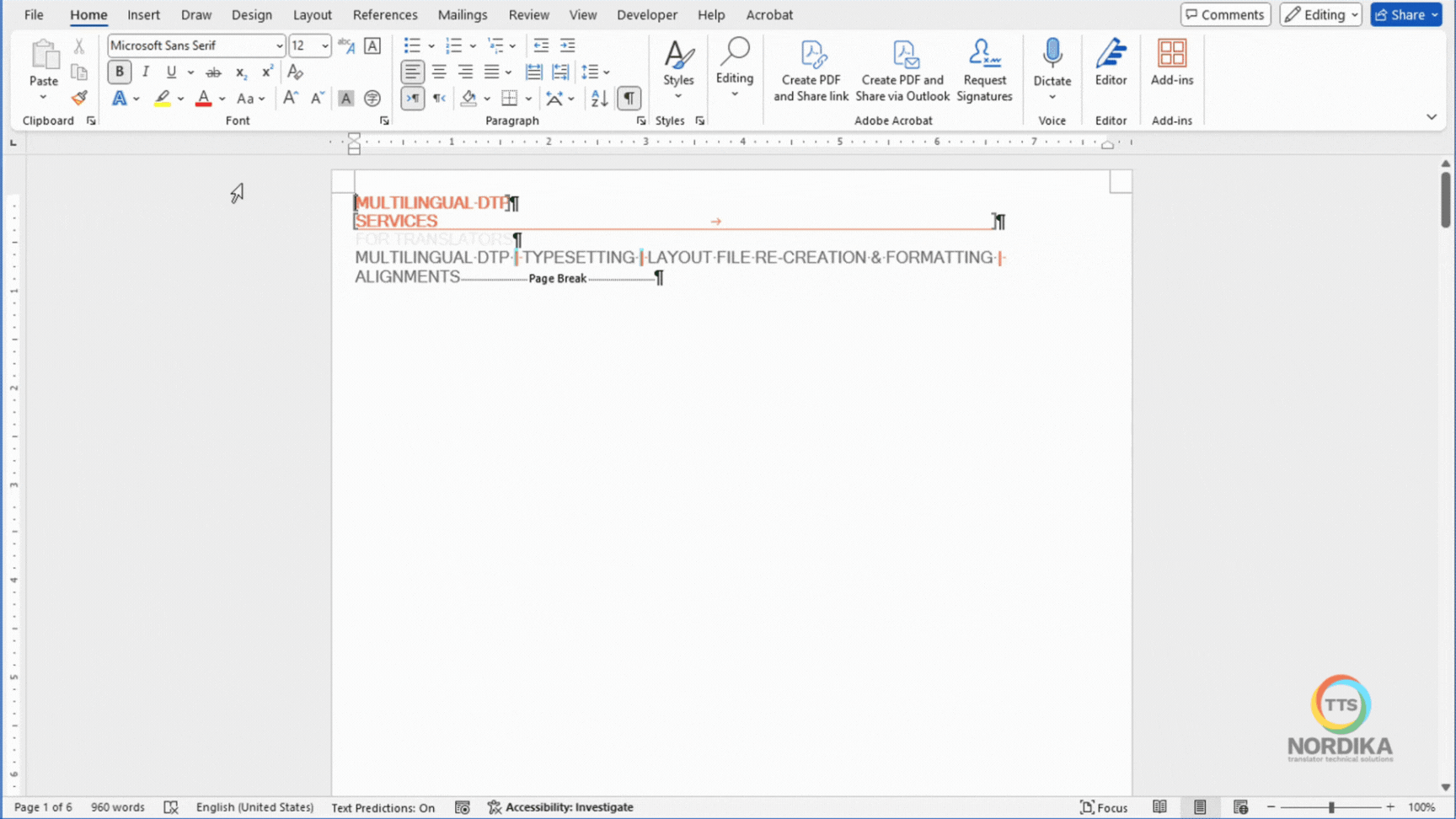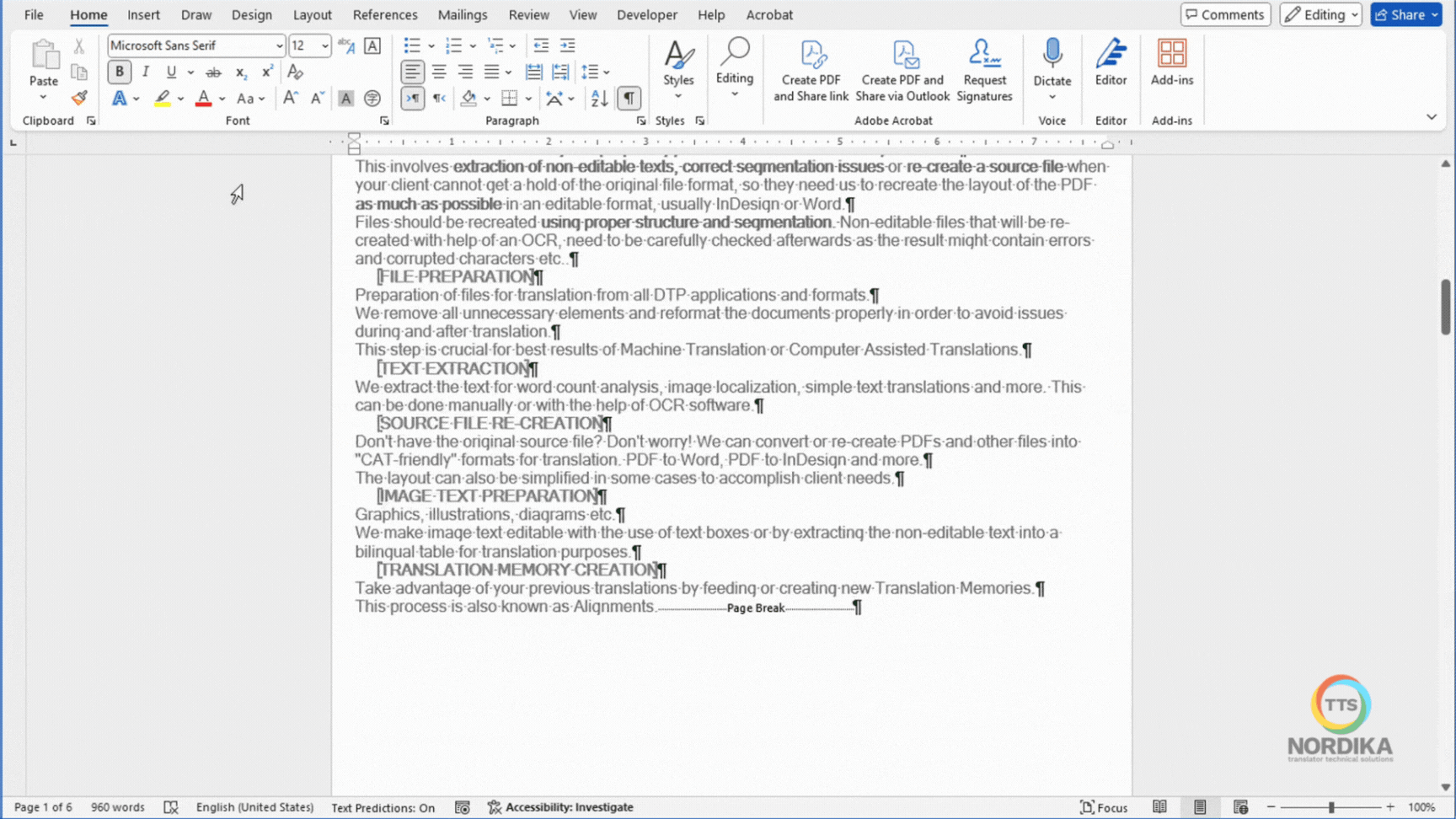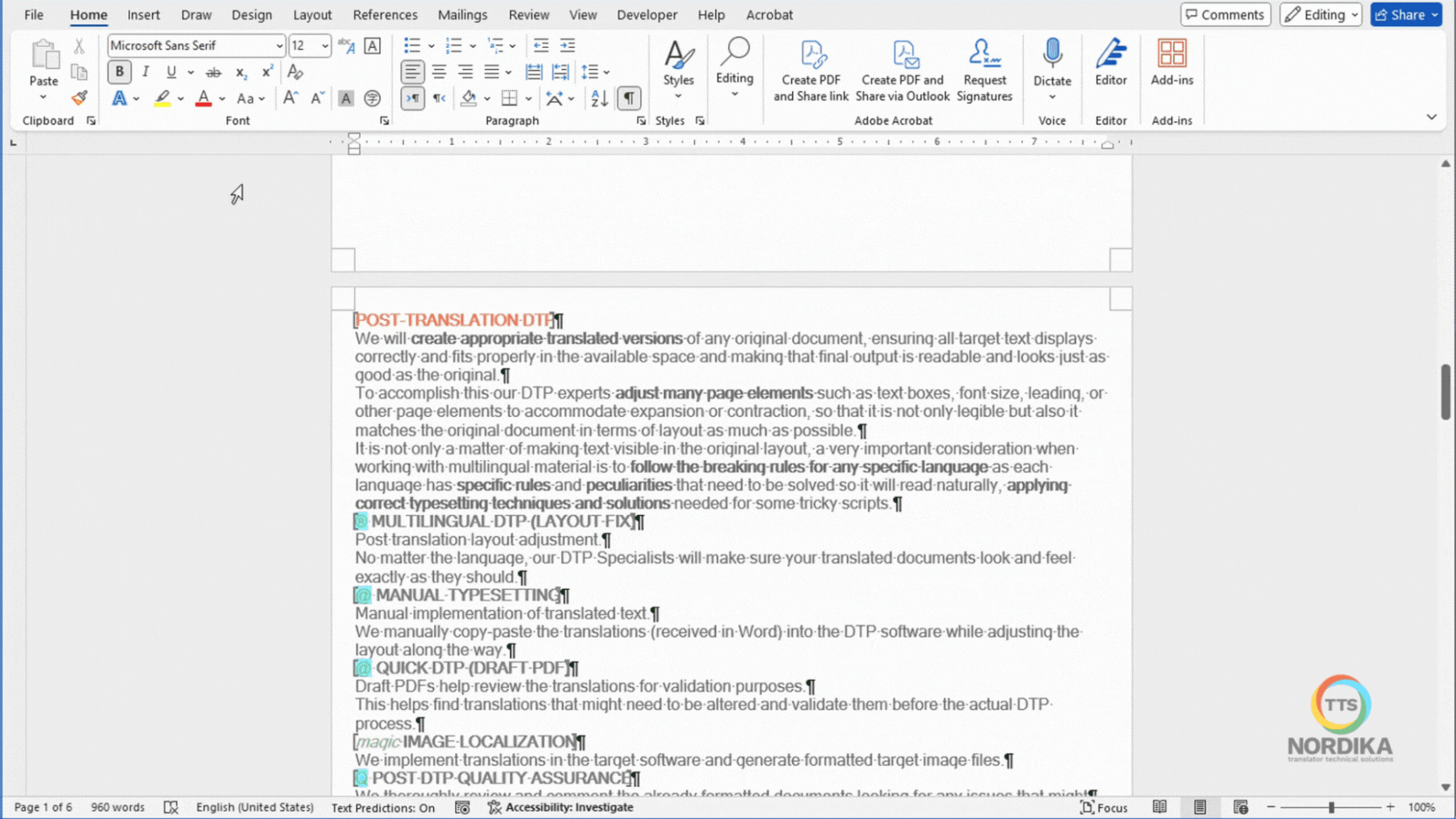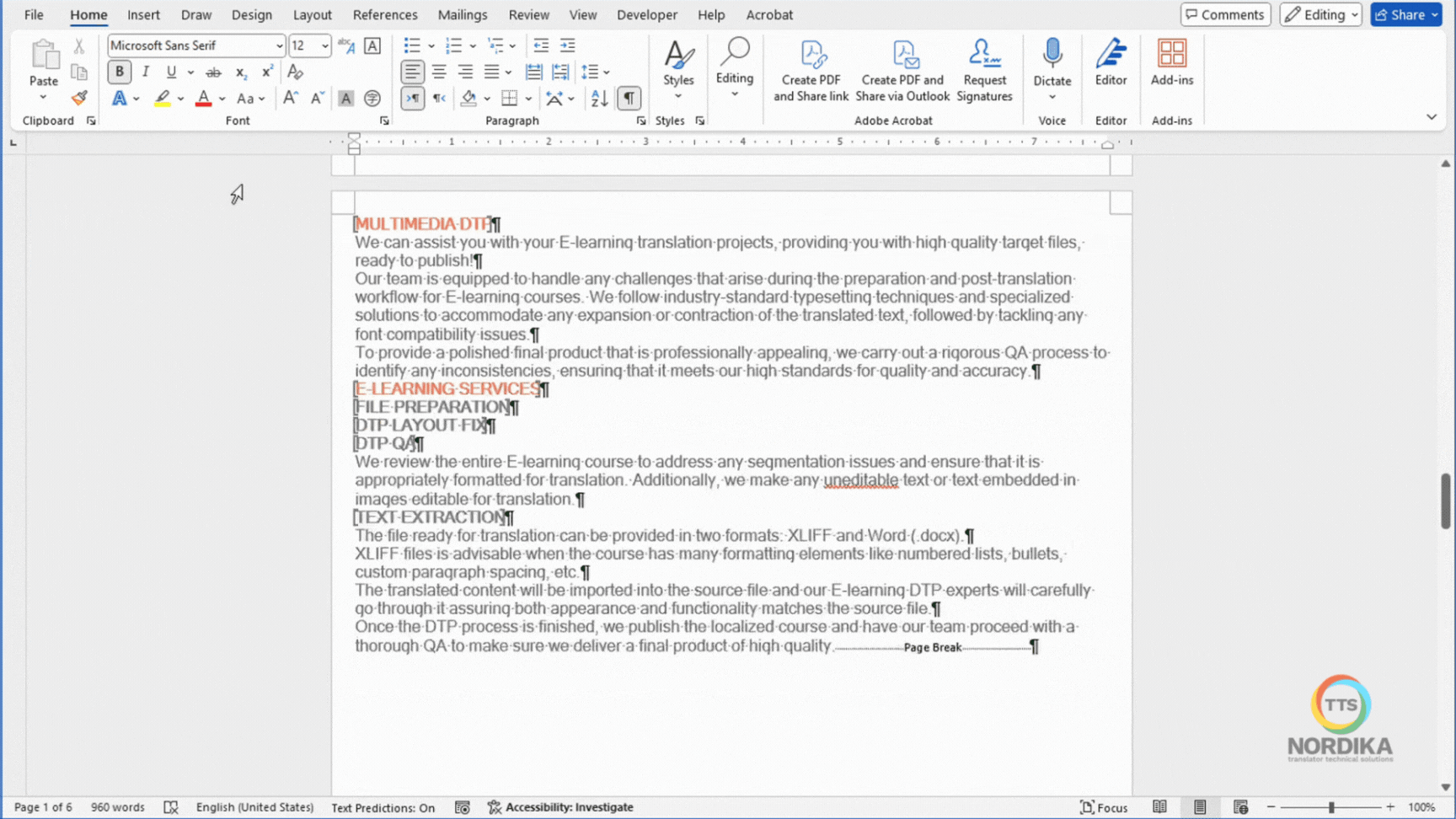
We have published a guide on how to re-create the layout of this document in Word. Check it out here!
7. Prepare Word document for translation
Please note that for optimal translation results, the Word document you obtain after converting the PDF should also be properly prepared for translation. Stay tuned for our upcoming article where we will guide you through the file preparation for translation process in Word.









